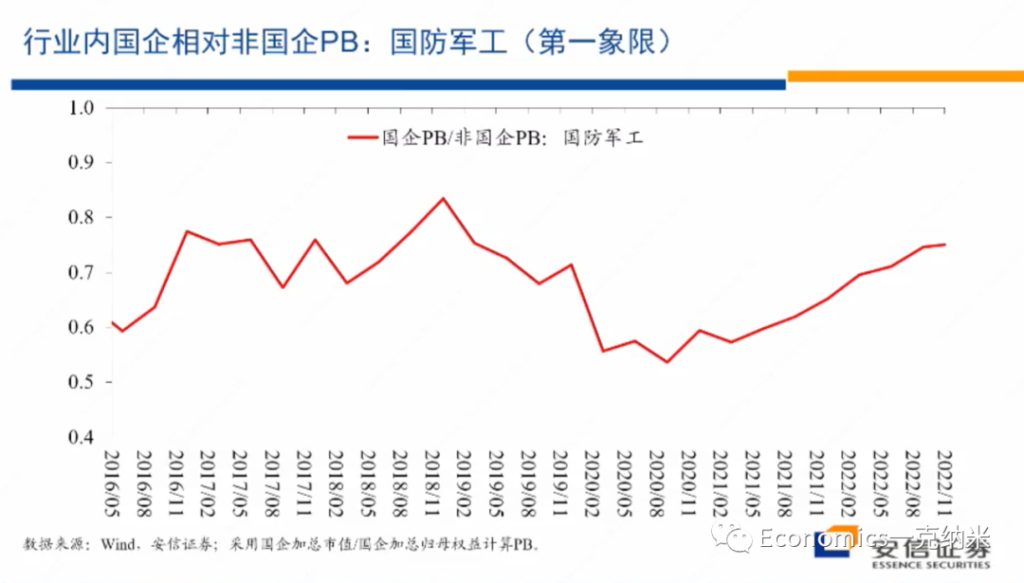
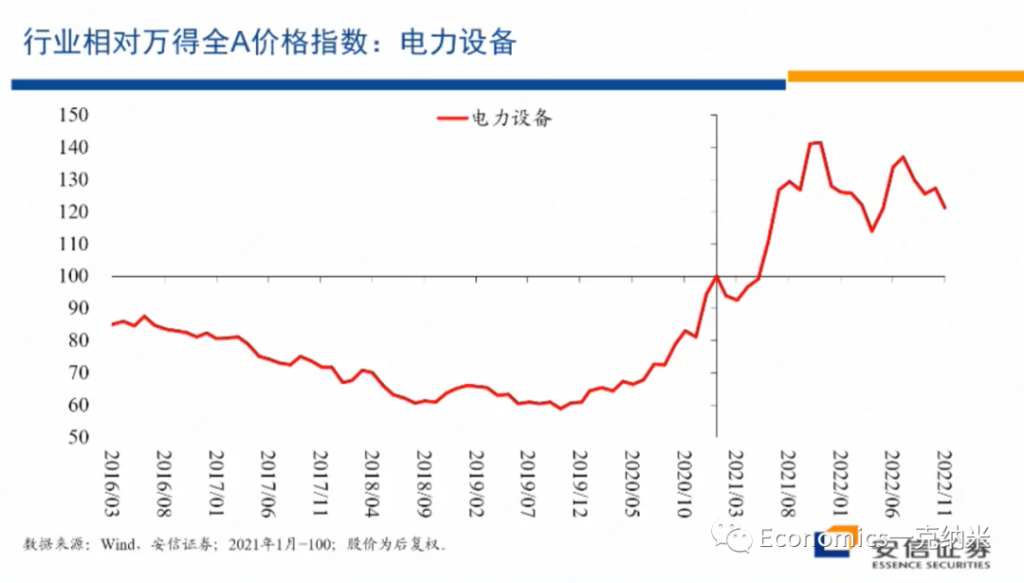
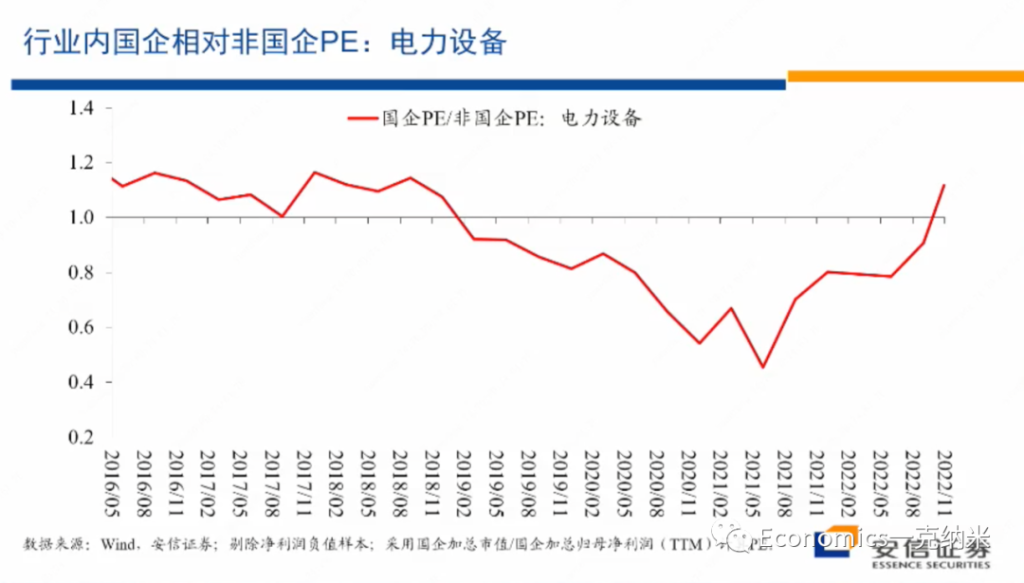
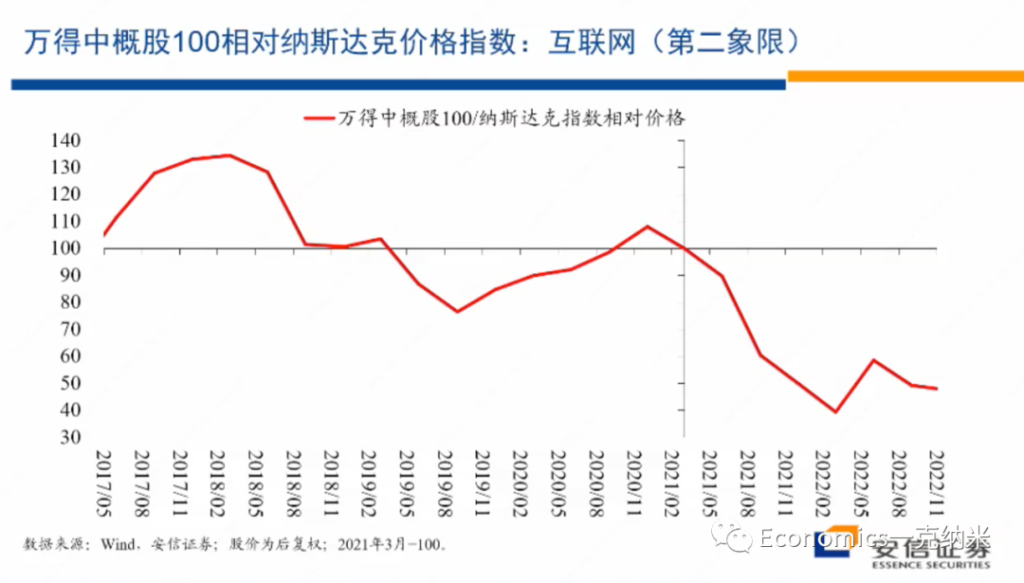
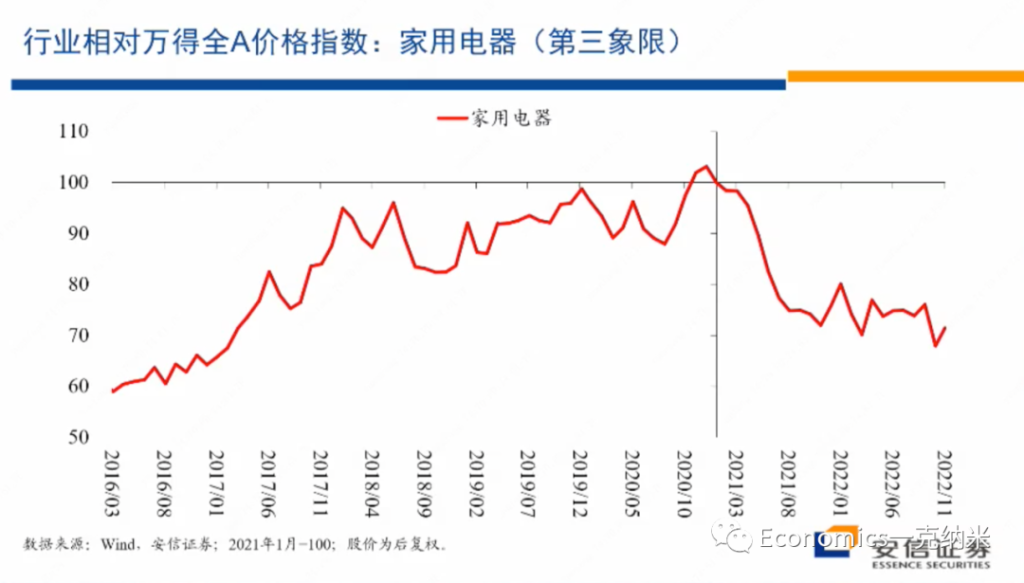
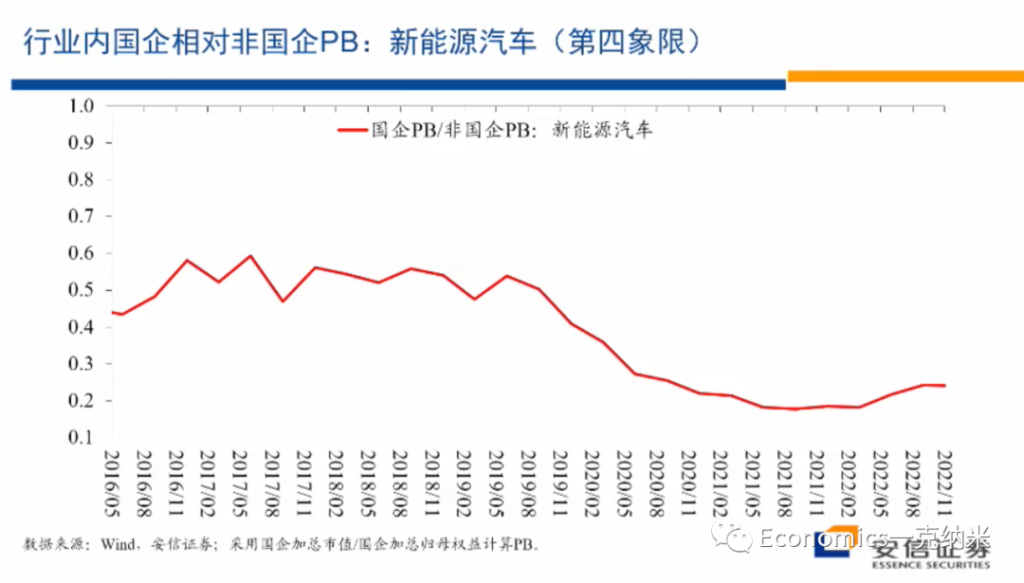
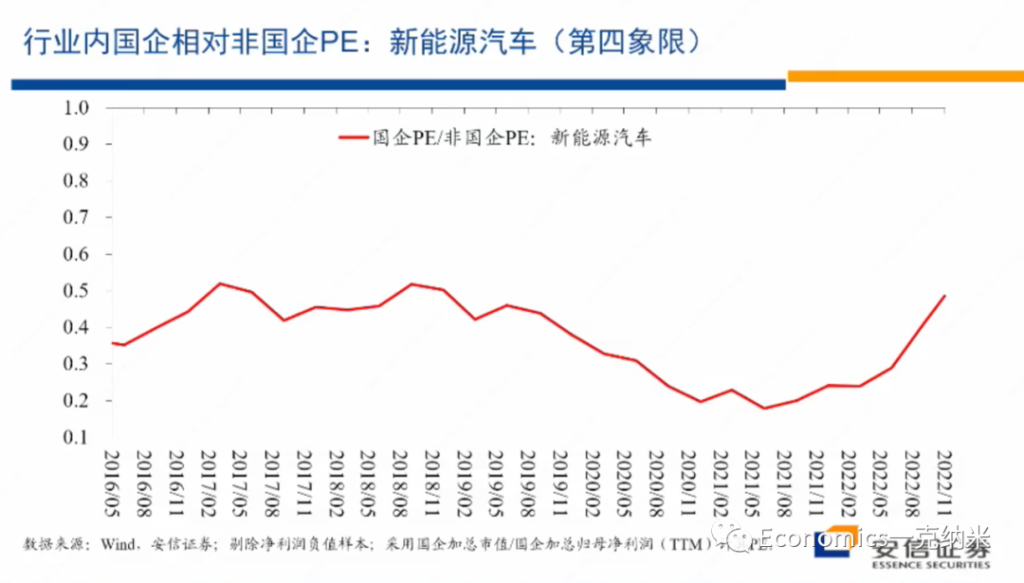
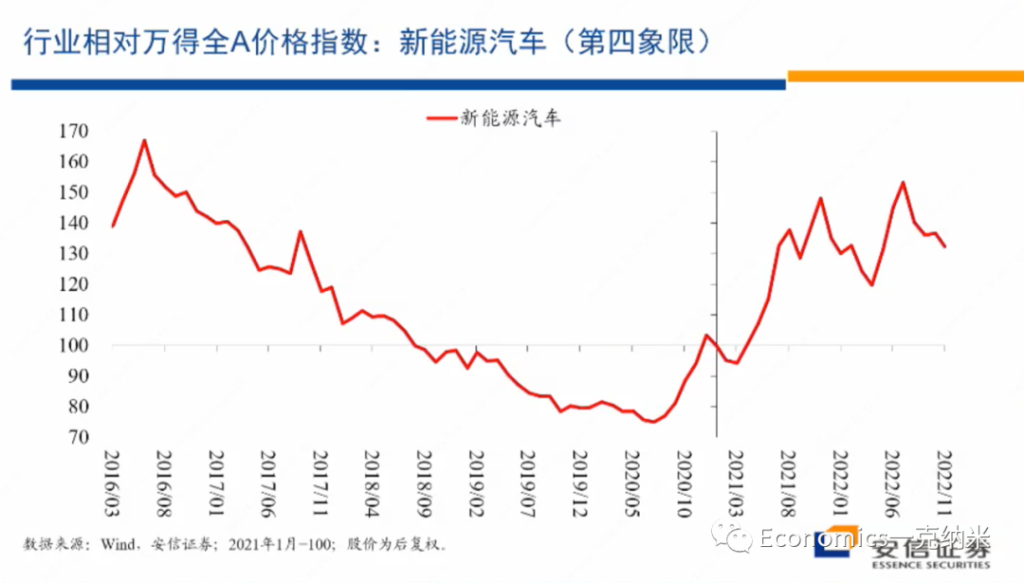
See my Github repo for full details.
https://github.com/eightsmile/cqf
1. Trinomial Random Walk
2. Transition Probability Density Function
The transition probability density function, p(y,t;y’,t’), is defined by,
$$ Prob(a<y'<b, at\ time \ t’ | y \ at \ time\ t) = \int_a^b p(yet;y’,t’)dy’$$
In words this is “the probability that the random variable y ′ lies between a and b at time t ′ in the future, given that it started out with value y at time t.”
Think of y and t as being current values with y ′ and t ′ being future values. The transition probability density function can be used to answer the question,
“What is the probability of the variable y ′ being in a specified range at time t ′ in the future given that it started out with value y at time t?”
Our Goal is to find the transition probability p.d.f., and so we find the relationship between p(y,t;y’,t’), and p(y,t;y’,t’-\delta t),
3. From the Trinomial model to the Transition Probability Density function
The variable y can either rise, fall or take the same value after a time step δt. These movements have certain probabilities associated with them.
We are going to assume that the probability of a rise and a fall are both the same, \alpha<\frac{1}{2} . (But, of course, this can be generalized. Why would we want to generalize this?)
3.1 The Forward Equation
Given {y,t}, or says {y,t} the current and previous. {y’,t’} are variate in the future time.
The probability of being at y’ at time t’ is related to the probabilities of being at the previous three values and moving in the right direction:
$$ p(y,t;y’,t’) = \alpha \ p(y,t;y’+\delta y,t’-\delta t) + \ (1-2\alpha) \ p(y,t;y’,t’-\delta t) + \alpha \ p(y,t;y’-\delta y,t’-\delta t) $$
Given {y,t}, we find relationship between {y’,t’} and {y’\pm \delta y,t’-\delta t} that is y’ and t’ a bit time previously.
Remember, our goal is to find a solution of p(.), we try to solve the above equation.
3.2 Taylor Series Expansion
We expand each term of the equation.
$$ p(y,t;y’,t’) = \alpha \ p(y,t;y’+\delta y,t’-\delta t) + \ (1-2\alpha) \ p(y,t;y’,t’-\delta t) + \alpha \ p(y,t;y’-\delta y,t’-\delta t) $$
Why we do that? Because there are too many variables in it, hard to solve it. We have to reduce the dimension.
$$ p(y,t;y’+\delta y,t’-\delta t)\approx \ p(y,t;y’,t) – \delta t \frac{\partial p}{\partial t’} +\delta y \frac{\partial p}{\partial y’} + \frac{1}{2}\delta y^2 \frac{\partial^2 p}{\partial y’^2} + O(\frac{\partial^2 p}{\partial t’^2}) $$
$$ p(y,t;y’,t’-\delta t)\approx \ p(y,t;y’,t) – \delta t \frac{\partial p}{\partial t’} + O(\frac{\partial^2 p}{\partial t’^2}) $$
$$ p(y,t;y’-\delta y,t’-\delta t)\approx \ p(y,t;y’,t) – \delta t \frac{\partial p}{\partial t’} -\delta y \frac{\partial p}{\partial y’} + \frac{1}{2}\delta y^2 \frac{\partial^2 p}{\partial y’^2} + O(\frac{\partial^2 p}{\partial t’^2}) $$
Plug them back into that equation, and after cancel out terms repeated we would left with,
$$ \frac{\partial p}{\partial t’} =\alpha \frac{\delta y^2}{\delta t} \frac{\partial^2 p}{\partial y’^2} + O(\frac{\partial^2 p}{\partial t’^2})$$
We drop those derivative terms with order greater and equal than O(\frac{\partial^2 p}{\partial t’^2}).
$$ \frac{\partial p}{\partial t’} =\alpha \frac{\delta y^2}{\delta t} \frac{\partial^2 p}{\partial y’^2} $$
In the RHS, we focus on \alpha \frac{\delta y^2}{\delta t}, firstly. The denominator and numerator have to be in the same order to make that term definite. Or, say \delta y \sim O(\sqrt{\delta t}).
We thus let c^2 = \alpha \frac{\delta y^2}{\delta t}
$$ \frac{\partial p}{\partial t’} =c^2 \frac{\partial^2 p}{\partial y’^2} $$
The above equation is also named Fokker–Planck or forward Kolmogorov equation.
Now, we have a partial differential equation. Solve it, we can get the form of p.
3.3 Backward Equation works similar.
$$ p(y,t;y’,t’) = \alpha \ p(y+\delta y,t+\delta t;y’,t’) + \ (1-2\alpha) \ p(y,t+\delta t;y’,t’) + \alpha \ p(y-\delta y,t+\delta t;y’,t’) $$
the dimension-reduced result is the blow, and it is called the backward Kolmogorov equation.
$$ \frac{\partial p}{\partial t’} + c^2 \frac{\partial^2 p}{\partial y’^2} =0 $$
4. Solve the Forward Kolmogorov Equation
We will solve for p right now! However, we will solve it by assuming similarity solution.
$$ \frac{\partial p}{\partial t’} =c^2 \frac{\partial^2 p}{\partial y’^2} $$
This equation has an infinite number of solutions. It has different solutions for different initial conditions and different boundary conditions. We need only a special solution here. The detailed process of finding that solution is showing as the following,
4. 1 Assume a Solution Form
$$ p=t’^a f(\frac{y’}{t’^b}) = t’^a f(\xi)$$
$$ \xi = \frac{y’}{t’^b}$$
, where a, and b are indefinite variables.
Again, don’t ask why it is in this form, because it is a special solution!
4.2 Derivation
$$\frac{\partial p}{\partial y’}=t’^{a-b}\frac{df}{d\xi}$$
$$\frac{\partial^2 p}{\partial y’^2}=t’^{a-2b}\frac{d^2f}{d\xi^2}$$
$$\frac{\partial p}{\partial t’}=at’^{a-1}f(\xi)+by’t’^{a-b-1}\frac{df}{d\xi}$$
Substitue back into the forward Kolmogorov equation (remember y’ = t’^b \xi), we get,
$$ af(\xi) – b\xi \frac{df}{d\xi} = c^2 t’^{-2b+1} \frac{d^2f}{d\xi^2}$$
4.3 Choose b
As we need the RHS to be independent of t’, we could choose the value of b=\frac{1}{2}, to let the t’ has a power of 0. Why we do that? Because we aim to reduce the partial differential equation to be a ordinary differential equation, in which the only variable is \xi, and t’ disappear.
By assuming the special form of p, and letting b= 1/2, our forward Kolmogorov becomes,
$$ af(\xi) – \frac{1}{2}\xi \frac{df}{d\xi} = c^2 \frac{d^2f}{d\xi^2}$$
$$ p=t’^a f(\frac{y’}{\sqrt{t’}}) = t’^a f(\xi)$$
$$ \xi = \frac{y’}{\sqrt{t’}}$$
4.4 Choose a
$$p=t’^a f(\frac{y’}{\sqrt{t’}}) $$
We know that p is the transition p.d.f., its integral must be equal to ‘1’. t’ is independent by the definition of random walk behaviour, so we do only integrate p, w.r.t. y’.
$$\int_{\mathbb{R}}p\ dy’ = \int_{\mathbb{R}} t’^a f(\frac{y’}{\sqrt{t’}})\ dy’ = 1$$
$$ \int_{\mathbb{R}} t’^a f(\frac{y’}{\sqrt{t’}})\ dy’ = 1 $$
, by replace x = \frac{y’}{\sqrt{t’}},
$$ \int_{\mathbb{R}} t’^{a+1/2} f(x)\ dx =t’^{a+1/2} \int_{\mathbb{R}} f(x)\ dx= 1 $$
$t’$ is independent, so the above equation would be equal to ‘1’ regardless the power of $t’$. Thus, $a = -\frac{1}{2}$ for sure.
Also, we get \int_{\mathbb{R}} f(x)\ dx= 1.
4.5 Integrate! Solve it!
By assuming the special form of p, and letting a=-1/2, b=1/2, we get,
$$ -\frac{1}{2}f(\xi) – \frac{1}{2}\xi \frac{df}{d\xi} = c^2 \frac{d^2f}{d\xi^2}$$
$$ p=\frac{1}{\sqrt{t’}} f(\frac{y’}{\sqrt{t’}}) = \frac{1}{\sqrt{t’}}f(\xi)$$
$$ \xi = \frac{y’}{\sqrt{t’}}$$
The forward Kolmogorov equation becomes,
$$ -\frac{1}{2}\bigg(f(\xi) – \xi \frac{df}{d\xi} \bigg)= c^2 \frac{d^2f}{d\xi^2}$$
$$ -\frac{1}{2}\bigg( \frac{d \xi f(\xi)}{d \xi} \bigg)= c^2 \frac{d^2f}{d\xi^2}$$
, as f(\xi) – \xi \frac{df}{d\xi} = \frac{d \xi f(\xi)}{d \xi}.
Integrate 1st Time
$$ -\frac{1}{2}\xi f(\xi)= c^2 \frac{df}{d\xi} + constant$$
There’s an arbitrary constant of integration that could go in here but for the answer we want this is zero. We need only a special solution, so we can set that arbitrary constant term be zero.
So, the eq could be rewritten as,
$$ -\frac{1}{2c^2}\xi d\xi = \frac{1}{f(\xi)}df $$
Integrate 2nd Time
$$ ln\ f(\xi) = -\frac{\xi^2}{4c^2} + C$$
Take exponential, f(\xi) = e^C e^{-\frac{\xi^2}{4c^2}} = A e^{-\frac{\xi^2}{4c^2}} .
Find A
The Last Step here is to find the exact value of A. A is chosen such that the integral of f is one.
$$\int_{\mathbb{R}}f(\xi)\ d\xi =1$$
$$ \int_{\mathbb{R}}A e^{-\frac{\xi^2}{4c^2}} \ d\xi = 2cA\int_{\mathbb{R}} e^{-\frac{\xi^2}{4c^2}} \ d\big(\frac{\xi}{2c}\big) =1 $$
$$ 2cA \sqrt{\pi} = 1 $$
, so we get A = \frac{1}{2c\sqrt{\pi}}
Plug f(\xi), a, b, A back into p = t^a f(\xi).
$$ p(y’)=\frac{1}{2c\sqrt{\pi \ t’}}e^{-\frac{\xi^2}{4c^2}} =\frac{1}{2c\sqrt{\pi \ t’}}e^{-\frac{y’^2}{4c^2t’}} $$
$p(.)$ now is normal like distributed.
$$N(x) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}$$
So, we may say \mu_{y’}=0, and \sigma^2_{y’}=2c^2t’. Or, y’ \sim N(0, 2c^2t’).
5. Summary
$$p(y’)=\frac{1}{2c\sqrt{\pi \ t’}}e^{-\frac{\xi^2}{4c^2}} =\frac{1}{2c\sqrt{\pi \ t’}}e^{-\frac{y’^2}{4c^2t’}} $$
Finally, we solved the transition probability density function p(.). By assuming the forward or backward type of trinomial model, we find a partial differential relationship. Then, assuming a special form of p(.) by similarity method, we solve it.
The meaning is that p(y’)=\frac{1}{2c\sqrt{\pi \ t’}}e^{-\frac{\xi^2}{4c^2}} =\frac{1}{2c\sqrt{\pi \ t’}}e^{-\frac{y’^2}{4c^2t’}} is one of the transition probability density function that can satisfy the trinomial random walk.
Also, we find that p(.) is normally liked distributed.