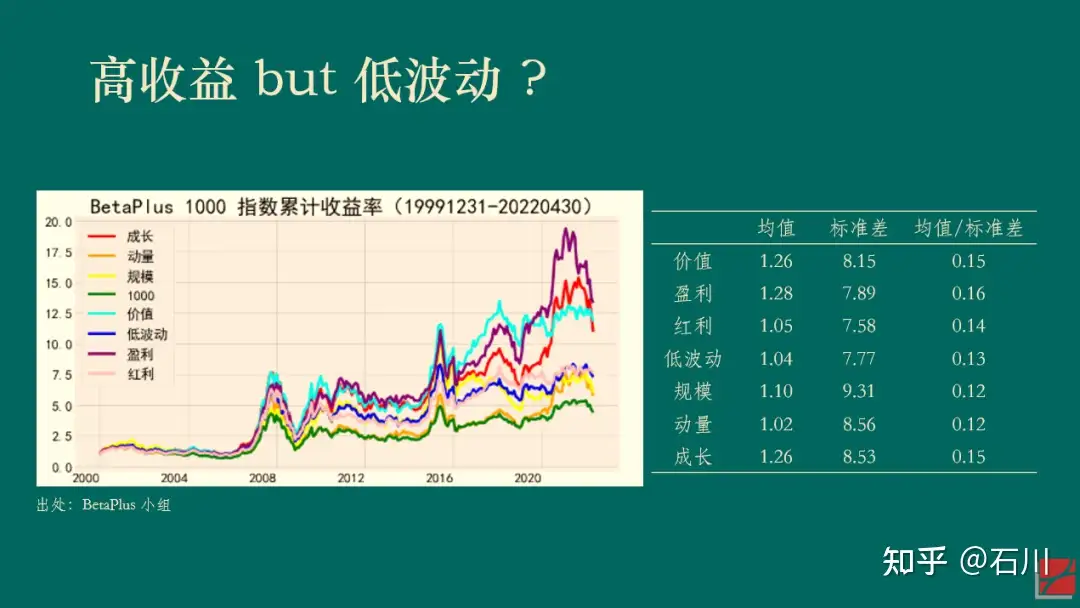
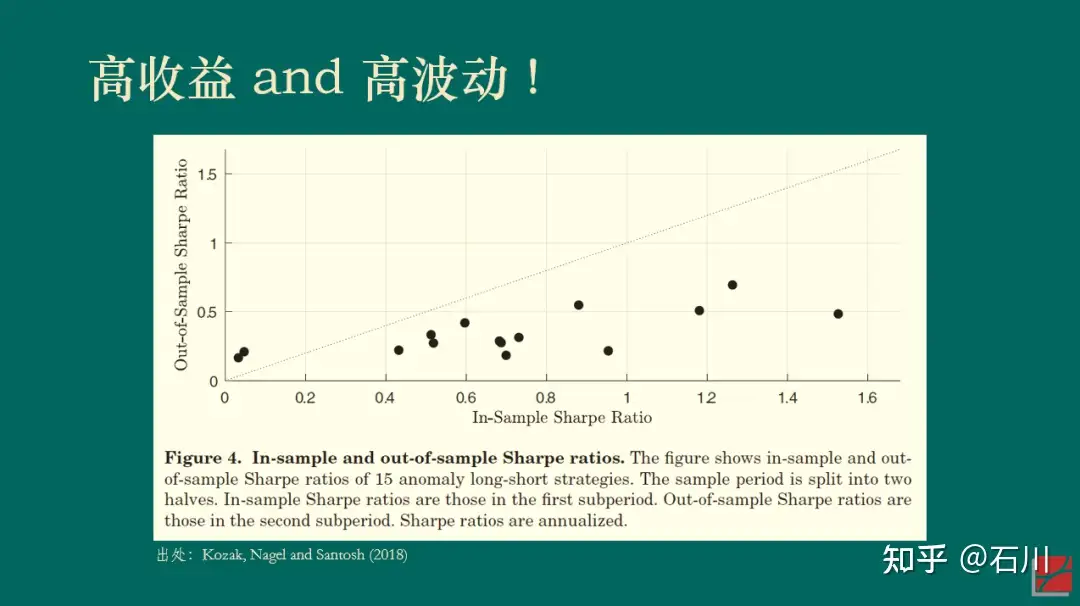
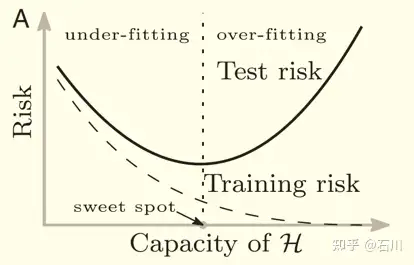
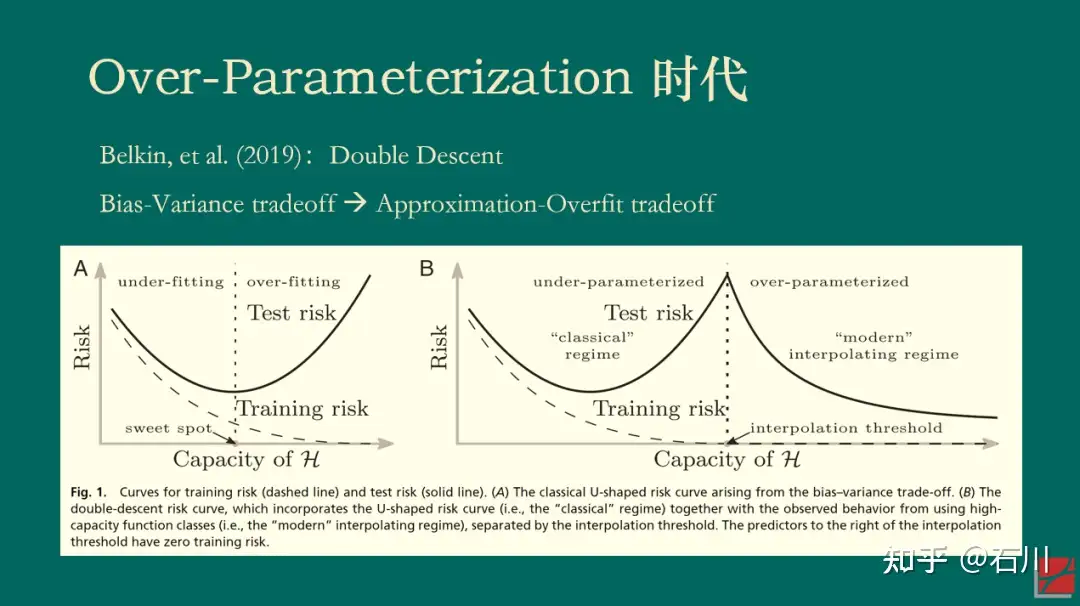
Allocating assets into different asset classes may depend on the (1) risk aversion, (2) time horizon, (3) tax status. And the (4) market timing also matters.
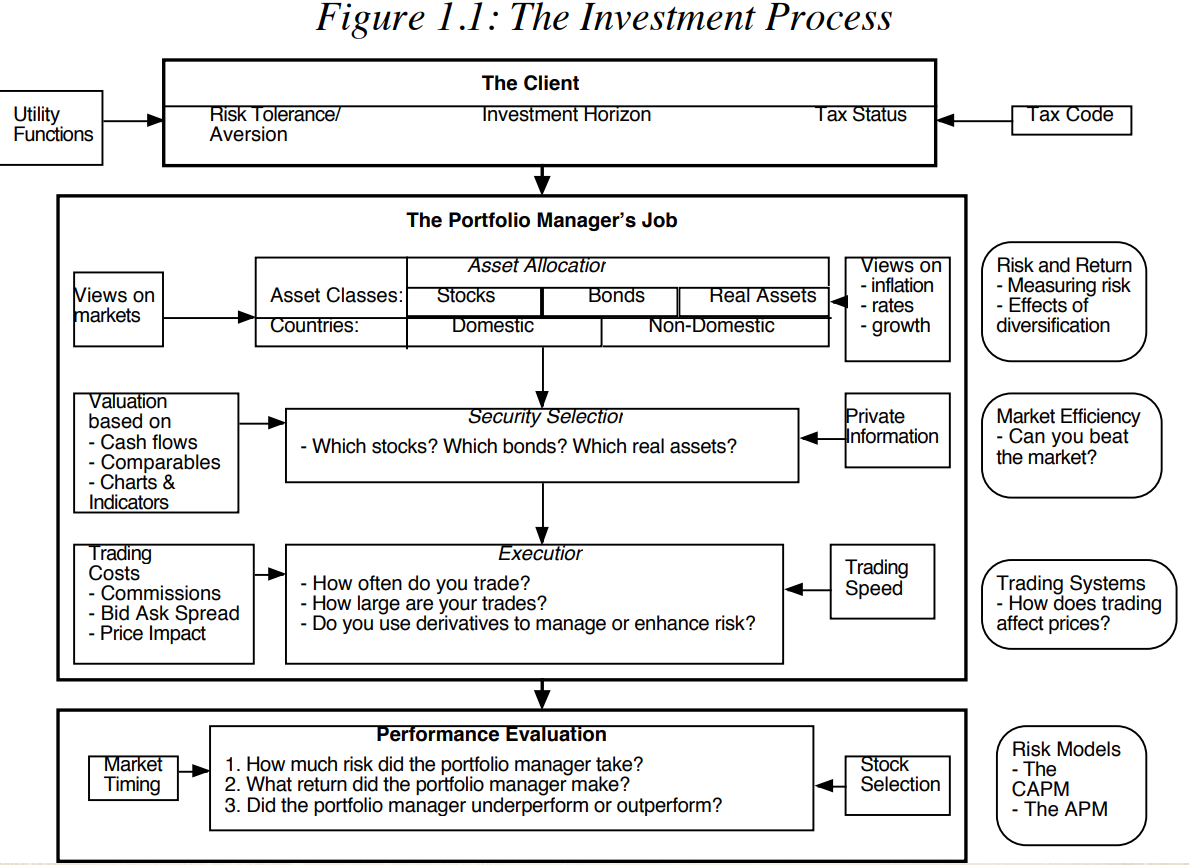
In other words, sensing the market timing would help you
- allocate assets into different asset classes such as debts, equity;
- be out of the market in the bad months, and get into the mkt in the good period.
Cost of Market Timing
- Out at the wrong time. Miss the opportunity of growth, i.e..
- Transaction Costs
- Taxes
Market Timing Approaches
Non-financial indicators
- Spurious indicators that may seem to be correlated with the market but have no rational basis.
- Though there is no reasoning, there may still have some statistical pattern. Do not ignore it.
- Those indicators give a sense of direction.
- Feel good indicators that measure how happy investors are feeling – presumably, happier individuals will bid up higher stock prices.
- The problem is that those indicators provide contemporaneous or lagging status of the market, may lack of predictability compared with the leading indicators.
- Hype indicators.
- Still the contemporaneous problem. Those factors tell the correlation right now, but do not have predictive power.
- Also, the abnormality can be tricky when the environment is shifting.
- Technical indicators, such as price charts and trading volume.
- Past prices (such as price reversals or momentum, January Indicator)
Hard to say the momentum or the reversal could stay for years.
- Trading Volume & Money Flow
-
Price increases that occur without much trading volume are viewed as less likely to carry over.
- And, very heavy trading volume can also indicate the turning points in the markets.
-
The money flow is the difference between uptick volume and downtick volume. People find there are some predictability for longer periods, in that the equity markets overall show momentum.
-
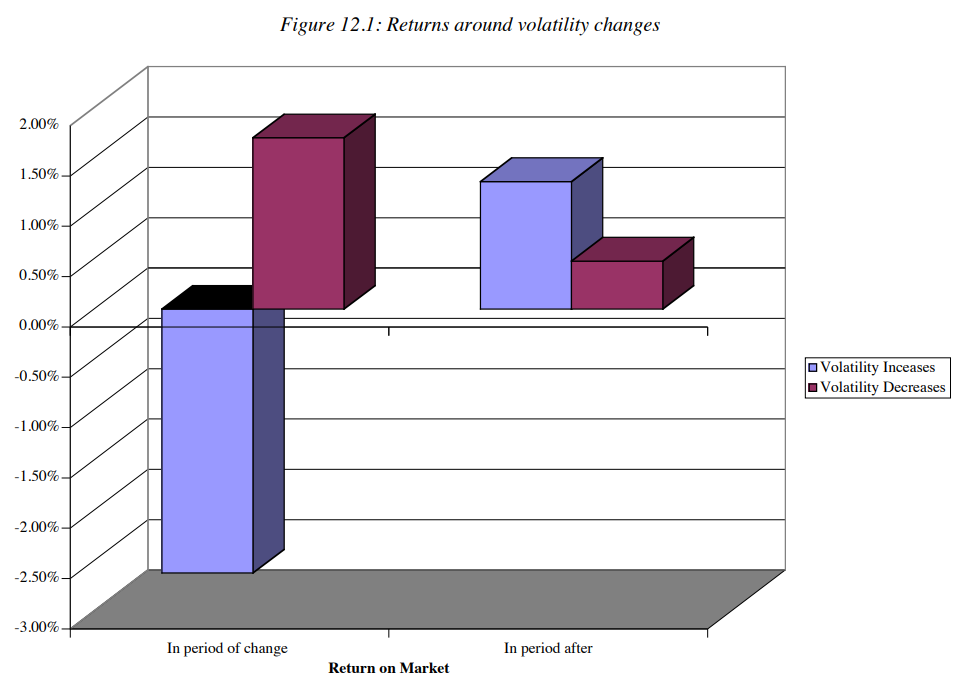
Market Volatility
-
Empirical research finds some evidence between the volatility change and returns.
-
See the blue bar: In periods that volatility increase and the market return goes down. After that period, the market is predicted to be like volatility increase and market return goes up.
-
Purple bar: in periods of volatility decrease and market return increase, the following period may have less volatility decrease and still returns.
-
Other price and sentiment indicators
-
Chart Patterns: supports and resistance lines are used to determine when to move in and out of individual stocks.
- Sentiment indicators: measure the mood of the market.
- Trader sentiments
Mean Reversion indicators, where stocks and bonds are viewed as mis-priced if they trade outside what is viewed as a normal range.
That approach is based on the assumption that stock price would revert to the P/E, and debt return would revert back certain interest rate.
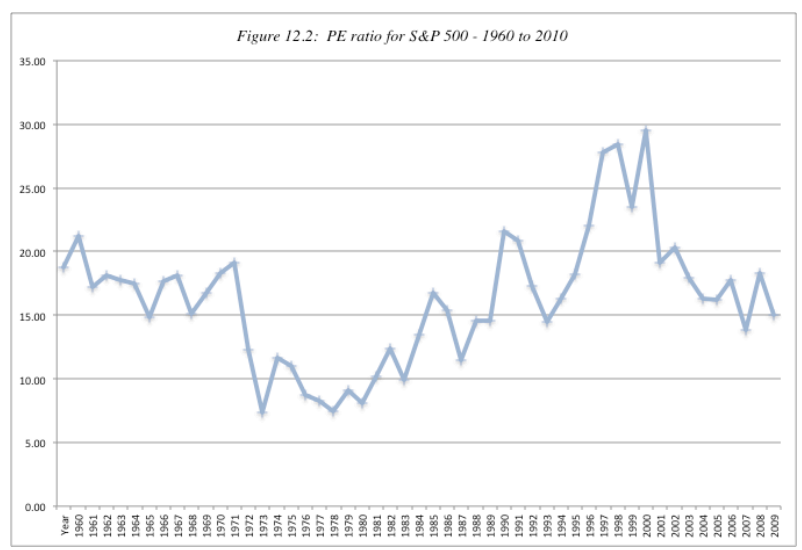
- P/E (see figure below for the normal range of P/E ratio)
If stock is above or below the normal P/E, then it is overvalued or undervalued. The median is around 16.
The P/E might go abnormally high in recession, not only because (1) the stocks are overvalued, but also because (2) the earnings are dropped down during recession.
-
Rate performs similarly.
\Delta Interest Rate_t = 0.0139 – 0.1456 InterestRate_{t-1}, where R^2=0.728. Coefficients are significant.
The regression suggest two things:
- Change in interest rates in the period is negatively correlated with the level of rates at the end of each prior year.
- The speed shrinks. For every 1% increase in the level of current rate, the expected drop in interest rate in the next periods increases by 0.1456%.
Fundamentals
Using the fundamentals to predict market timing is to focus on macroeconomic variables such as interest rate, inflation and GNP growth and devise investing rules based upon the levels or changes in macro economic variables.
Two keys of using this approach. (to build up the logic chain of prediction)
- Get handle how the market reacts as macro econ fundamentals change.
- Get good predictions of changes in macro econ fundamentals.
- Macro economic variables, such as the level of interest rate or the state of the econ cycle.
There are some common sense that the following changes would indicate the increase in stock price:
- Buy when Treasury bill rates are low, will end up with growth of stock price.
- Buy when Treasury bond rates have dropped, will end up with growth of stock price.
- Buy GNP growth is strong, will end up with growth of stock price.
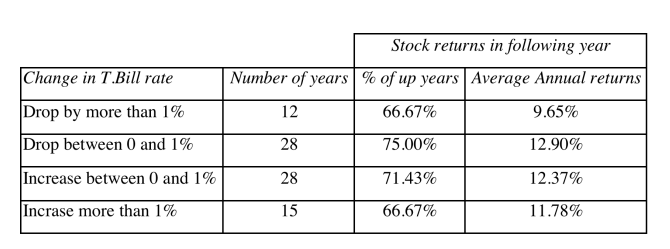
However, empirical evidence shows the other way. For example, the table below shows T-bill rate drops or increases could both contribute to the increase in Annual returns.
Valuing the Market
Just as you can value individual stocks with intrinsic valuation (DCF) models and relative valuation (multiples) models, you can value the market as well. If the valuation is faithful, you can reply on it to predict the market timing.
- Intrinsic valuation that apply to the mkt. <- depends on assumptions and inputs.
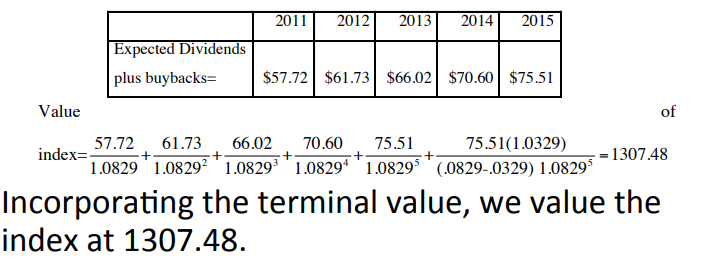
Use the S&P500 price and the index’s dividends to do the DCF.
INPUTs: (1) S&P500 price, 1257.64 at 2011(2) Dividends and buyback on the index amount over previous year, 53.96 (3) expected earning growth for the following 5 years, 6.95% (4) expected growth of the economy (set as risk free rate) 3.29%, (5) treasury bond rate, plus the market risk premium (set it yourself) 5% to get the cost of equity 3.29%+5%=8.29%. Then, do the DCF
-
Relative Valuation <- value a market relative to other market, or across years.
-
Other methods, such as run regression on P/E to T-bill to find correlation.
Does the Market Timing Work?
-
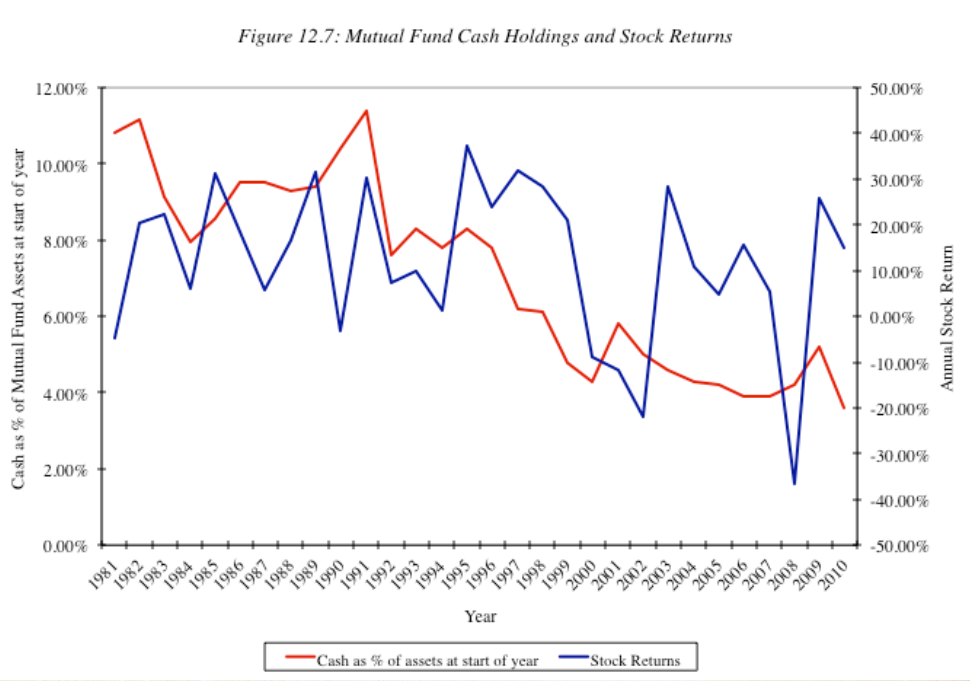
Mutual Fund Managers: constantly try to time the markets by changing the amount of cash that they hold in the fund. If expected bullish, then cash balances decreases, vice versa.
They call timing the market as Tactical Asset Allocation, TAA.
See figure below, empirical evidence shows they do predict the market by changing the cash position.
-
Investment Newsletter: often take bullish or bearish view about the market.
There is continuity on Newsletter way. Investment newsletters that give bad advice on market timing are more likely to continue to give bad advice than are newsletters that gave good advice to continue giving good advice. In other words, it depend on the writer’s ability.
-
Market strategists: make forecast for the overall market.
-
Professor Market Timers provide advice, however, their decision works for very short time, and only work for private clients.
Market Timing Strategies
- Adjust Asset Allocation: change across asset classes
- Switch Investment Styles: change within asset classes but different styles, such as from growth to value.
- Sector Rotation: with in asset classes, but different sector.
- Market Speculation.
Market Timing Instruments
- Futures Contracts
- Options Contracts
- ETFs
Implications and Insights
Overall, it’s good summary and a Beginner’s Tutorial, but not include technical implementation method, instruction, or philosophy.
Do provide some inspirations.
Reference
https://pages.stern.nyu.edu/~adamodar/New_Home_Page/webcastinvphil.htm